
我的博客是2022年从Wordpress换成Hugo的,受制于Hugo这种纯静态框架的限制,必须要额外再配备评论系统。当时Waline等产品只能使用Leancloud作为数据库,所以为了省事直接用的Disqus,后者是可以直接接入Wordpress的,因此可以非常简单地转移到Hugo,并且使用DisqusJS这样的项目并配合反向代理的话体验还不错。但到了现在,即便使用了Vercel的反代,Disqus的体验也很难说好,且我还多次收到反馈说有用户根本没法加载Disqus评论区。为了能有个阳间一点的体验,是时候换个新的了。
评论系统的选择
我的Hugo主题是Stack,它内置支持了不少评论系统,所以直接在兼容列表里面选择是最方便的。
其实当前评论系统无非两类:
一是Giscus、Gitalk这类利用Github Discuss或者Issues的,很方便搭建且无需再配备数据库,使用GitHub登录也一定程度上避免了Spam,但缺点也是GitHub:它必须也只能使用GitHub(或类似平台)登录;另一类比如Twikoo、Waline就支持匿名评论,和WordPress的体验完全一致,但缺点是需要自行配备数据库存储评论。
我个人来讲还是更希望使用类似WordPress那样的匿名评论系统,无需登录,仅需留下邮箱和昵称即可直接评论;同时访客也并不一定有GitHub账号。当时使用Disqus其实也有这个原因,因为Disqus其实也是可以不用注册账号就能评论的。
基于上面的需求且比较适合国人的就只有Twikoo和Waline了。
Twikoo是个新一点的评论系统,使用MongoDB,我个人感觉相较于Waline来讲要更简约简单一点。但有一个问题:太简单了。它没有单独的后台,只能自己找一个使用了Twikoo的页面进入管理面板,且这个面板不能在新页面中打开而是就评论区里面原地启动,显而易见地这个面板的展开面积就很小了。虽然GUI可修改的各种自定义项目很多(但主题都已经适配好了,所以一般来讲是不需要动的),管理起来是真的有点麻烦。如果有个独立面板就更好了。
另一个大问题就是,我们都知道这些评论系统是通过文章URL来判断并输出对应文章的评论的,Twikoo配置的文章URL是使用的绝对路径而非相对路径,但我这个博客现在绑定了2个域名,且后续我想把cysi.me这个顶级域名也改成博客本体,如果评论对应的文章URL全是绝对路径(如https://example.com/post/1)而非相对路径(如/post/1),一旦域名更换就必然无法识别。
至于Waline,已经存在挺久了,且现在还在活跃更新,用户群也不少。早年它只能用Leancloud数据库,当时因为这个也走了点弯路去用了Disqus,但现在它还支持MongoDB等多种数据库了。我最终也选择使用Waline。
搭建和配置Waline
使用MongoDB+Vercel搭建
我使用的是Vercel+MongoDB的组合,其中Vercel的部分可以参考官方文档。需要注意的是,官方文档的“快速上手”是基于Leancloud数据库的,如果不想使用Leancloud(比如我这种使用MongoDB的)则需要修改Vercel那边对应的环境变量,具体可以查阅这里。
总体来讲搭建并不算难,但MongoDB这边会有个坑,MongoDB默认给的URI是mongodb+srv://格式的,可以让客户端自动从DNS获取Seedlist服务器列表,但Waline的MongoDB实现比较老,并不支持+srv自动获取完整服务器列表(如果直接使用新版URI,Waline会出现500错误),必须获取旧版的mongodb://格式链接从而提取出服务器地址。
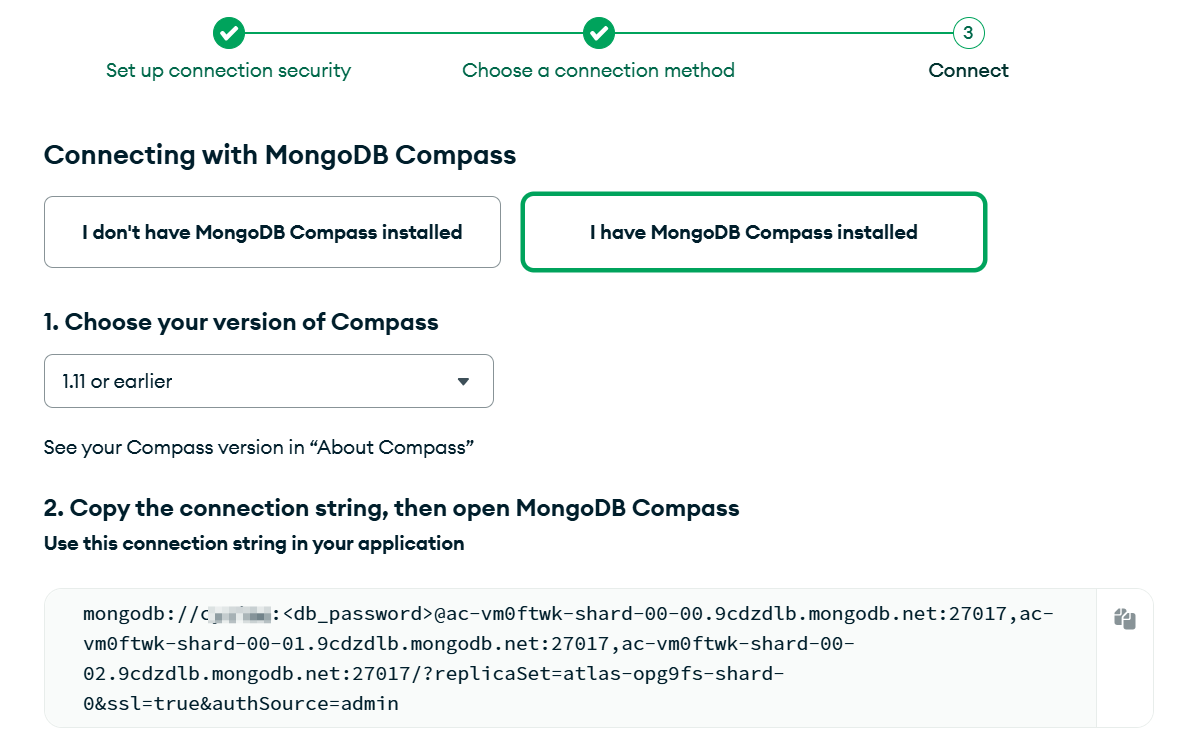
因此,我们需要在MongoDB面板中,点击Connect,并选择Compass,如上图一样选择“I have MongoDB Compass installed”,版本选择“1.11 or earlier”,你会得到类似这样的URI。
| |
可以看到这上面有3个服务器地址,我们提取出来。然后缝合进Waline官方已经整理好的环境变量里面,并将其设置进Vercel项目内即可。Waline部署完成后,访问https://<your-site-url>/ui即可进入后台并创建用户即可。
| |
评论迁移
迁移也并不困难,先去Disqus的导出数据页面导出并下载数据,再在Waline官方提供的迁移助手转换即可,记得要选对Waline的数据库格式。如果是MongoDB,导出的数据是CSV格式。
正常情况下,直接在MongoDB那边导入这个CSV数据到Comment数据表里面就行了,MongoDB官方有一个GUI管理工具Compass,可以直接导入CSV文件, 官方也同样提供了相应教程。如果不需要修改数据,导入CSV到指定数据库里面就算完成了,这时候评论系统也可以正常使用且旧评论都会正常迁移过去。
整理文章
但我这里情况比较特殊,我的博客已经跑了10多年了而且期间变过很多次永久链接格式(Permalink),而且还变过网站架构(Wordpress变成Hugo),这一系列操作下来,结果就是我的博客的链接格式是很混乱的,比如有的链接末尾带了/而有的没有。另一个问题是,我之前启用了Hugo的uglyURL功能,它会在博客内所有页面添加.html的后缀,致敬早年SEO的伪装静态文件的做法(实际上是因为我当时WordPress链接就是这样子的格式,为了保留后缀所以启用了这个功能),但这个uglyURL功能仅对Hugo设置中的baseURL对应域名才有效,且baseURL仅能设置一个——但我的博客有多个域名,也就是说,我现在只有https://blog.cysi.me这一个域名底下的URL后缀会带有.html而其他任何域名都不会有,除非我在每个Markdown文件的slug或者url字段都添加该后缀。
而Waline这些评论系统是靠文章URL来输出对应URL下的评论内容的,即便它使用的是相对路径,理论上不同域名只要URL结构一样也不会出问题,评论都可以正常在各个域名中正常共享,但基于我上面的情况,还是引发了两个坑:
- Waline会把同URL但末尾带或者不带
/的链接认为是2个不同文章,同理,带或者不带.html后缀也是会被识别成不同的文章的。Waline实际上提供了一个解决方案,就是在客户端处增加一个path属性,但我添加了这个字段没有起作用,所以我就开始考虑直接修改数据库的内容,此举顺便也是为了整理和梳理我博客混乱的永久链接的格式,将所有文章URL的格式统一。 - 要完全统一URL格式,就必须关闭
uglyURL功能,也就说所有的.html后缀都将会被移除,但此时访问带有.html后缀的URL都不会正常跳转并直接报错404。
好在这两个问题解决起来不难,第1个问题,上一步里面使用迁移助手转换得到的CSV文件,可以直接使用编辑器进行编辑,具体步骤就不必赘述了,毕竟现在让AI帮忙也很简单,然后再导入进MongoDB,会比直接在MongoDB上面使用数据库语句要方便点。Hugo默认情况下,文章URL末尾均带有/后缀,因此,我就要使用编辑器将CSV里面的评论URL字段,去除所有不必要的后缀(比如.html)并再在末尾都统一添加上/。
接下来处理问题2,关闭了uglyURL之后,实质上我现在的URL格式已经得到统一,但还是得做一个跳转(至少是旧的文章需要做跳转),避免出现404问题。其实Vercel等平台是可以直接跳转的,只需要在vercel.json内设置跳转即可,但我碰巧使用了多个平台(不同域名使用了不同的部署平台),经过考量我决定直接在Markdown的Frontmatter元数据里面设定aliases字段(也就是别名),我们可以在别名中添加.html后缀,这样就可以自动跳转了。这种办法的好处是完全不挑平台支持跳转与否,完全通用。直接让Gemini生成了个Python脚本,这个脚本会递归扫描指定目录,处理所有 .md 文件,并按照此逻辑优先级执行:
- 有 aliases -> 跳过。
- 无 aliases 但有 url -> 新增 aliases 为 url内容.html。
- 无 aliases 且无 url,但有 slug -> 新增 aliases 为 slug内容.html。
运行该脚本后,我所有文章都会添加一个带有.html后缀的别名,访问后会自动跳转Hugo的标准无后缀的URL上,避免出现404错误。
| |
完成
至此,整理工作终于完成,文章URL得到了整理和统一,评论系统也正常工作,旧的评论也正常显示。唯一问题是所有评论者的头像(即邮箱)、网站链接都会被抹掉,但可惜的是这个无法解决,因为Disqus的原始数据里面根本就不提供这些信息,且为了隐私保护,Disqus的后台是无法看到用户的邮箱的。
其实这次折腾更多是整理博客的结构,当初迁移到Hugo的时候太匆忙,细节上没有做好,现在再擦屁股考虑的事情就多了,不过趁此机会把之前遗留问题都清理了一下,整个Hugo的结构也看起来更干净了,还是不错的。